The Sentence Corpus of Remedial English (SCoRE) is a free, open-platform, web-based data-driven learning (DDL) program.
Research has shown that DDL (i.e., in this case, observing grammar and vocabulary in a variety of authentic contexts to understand language use) is effective for intermediate and advanced level second language learning. DDL can be used at the beginner level, however, existing corpora contain high level vocabulary, complex grammar and culturally obscure colloquial usage and are often paired with tools designed for researchers or more advanced level users which can be difficult for lower level proficiency users to negotiate. The purpose of this program is to provide both a level-appropriate corpus and set of tools easily used by lower level proficiency second language learners, teachers and material developers. It requires no fee or registration and its open platform allows users to contribute to its database.
It currently contains 22 categorized grammar items with over 10,000 level-specific, semi-authentic sentences written to satisfy particular pedagogical considerations, i.e., appropriateness and usability, and fair use for copyright issues. Each English example sentence is accompanied by a Japanese translation which was manually translated and corrected
It contains four tools:
(1) a pattern browser in which users can view example sentences by grammar item, keyword, and/or beginner, intermediate or advanced proficiency level;(2) a simple, user-friendly concordancer which displays results either as complete sentences or as key words in context (KWIC) and allows for sampling and sorting;
(3) a fill-in-the-blank quiz function (except English version) for creating quizzes and automatically marking answers aimed at motivating learners by providing instant feedback; and;
(4) a download function so that desired SCoRE data can be obtained in an EXCEL format to allow teachers create worksheets, quizzes, and homework.
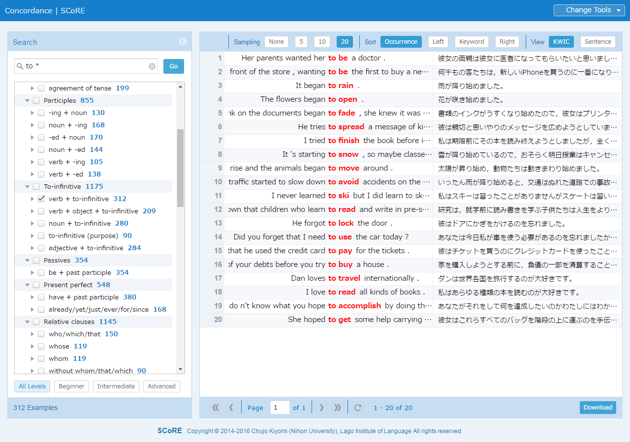
From within each tool, other tools can be chosen without returning to the top page (home page) by clicking on the pop-down menu on the upper right, shown below. For details, see User Guide.
Content on this site created by the SCoRE Project is licensed under the Creative Commons Attribution- NonCommercial- ShareAlike 4.0 International (CC BY-NC-SA 4.0) License. Any materials created from this program must cite and reference SCoRE.
Use the following reference to cite the SCoRE:
| Chujo, K., Oghigian, K. and Akasegawa, S. “A corpus and grammatical browsing system for remedial EFL learners,” In A. Leńko-Szymańska and A. Boulton (eds.), Multiple Affordances of Language Corpora for Data-driven Learning. Amsterdam: John Benjamins, 2015, 109-128. |
For more information on the research foundations of this work, background of DDL, or studies on the efficacy of DDL at the beginner L2 level, please click to Publications and Presentations on the left-side menu.
SCoRE was created from a 30-million-word database comprised of carefully selected English textbooks used in Asia, English graded readers, and children’s website content. From this database, specifically targeted grammar patterns were extracted. High frequency keywords within patterns were noted (e.g. most common verbs appearing in a particular phrase of clause), and then sentences were written in consideration with word familiarity, sentence length and usefulness.
As of 2016, SCoRE is the only known corpus that can be accessed by choosing a specific grammatical category, and was created in response to a needs analysis of second language teachers in Japan. The grammatical categories were chosen based on findings from Chujo, Yokota et al. (2012). In that study, a basic grammar proficiency test previously created to investigate the English proficiency levels of junior and senior high school students was administered to first year university students. Test items that were incorrectly answered by more than 30% of the participants were selected for inclusion in SCoRE. Thus the categories are common grammar patterns, including those found on proficiency tests such as TOEIC, but are not well understood by many Japanese junior and senior high school students. In other words, the grammatical categories were chosen by what lower level students were missing or were weak in, not the grammar patterns that were most frequent in a general, native-speaker corpus, or for example, those listed in the table of contents of a standard ESL textbook. Some examples are possessive pronouns, plural forms of nouns, the present perfect, subjunctives, relative clauses, and prepositions. As of the third phase of development, SCoRE contains 22 grammatical categories.
SCoRE is organized into sub-categories defined by keywords and further organized into three proficiency level (beginner, intermediate, advanced) level sentences with Japanese translations.
In addition to choosing a grammatical category, users can choose a sub-category by keyword. For example, for the pattern <have + past participle>, users can view examples sentences for have got, have been, have seen, have gone, have done, have come, have made, have given, have lost and have changed. These keyword verbs were chosen based on their frequency in the original 30-million-word database, and confirmed in a general corpus (COCA) as in fact being high frequency in English and therefore useful for our target population.
The determination for level was based on the findings of Chujo et al. (2007, 2011, and 2012) who identified the word familiarity and grammar level of Japanese senior high school graduates as commiserate with US grade 5. Optimal sentence length was based on findings from Chujo et al. (2007, 2011, and 2012), with beginner level sentences at eight words or less (e.g. What is it called?), intermediate at between five and eleven words (e.g. My little brother was called Tommy by his friends.), and advanced at more than nine words (e.g. She has been called a genius by her contemporaries.).
Although sentences were available in the 30-million-word database, it was important that users be able to download and incorporate the SCoRE sentences into classroom resources or teaching material and therefore needed to be copyright free. In addition, it was found that many original sentences did not make sense out of context or used allusions or low frequency words not applicable or particularly practical to target learners. Because the database sentences were from children’s resources (grade 5 or approximate age 11), topics more suitable for university students, and references to contemporary technology and culture modern expressions were included. For more information of the creation of the sentences or the development of SCoRE, please see Chujo et al (2015).
| ■Project Leader |
| Kiyomi CHUJO (Nihon University, Japan) |
| Shiro AKASEGAWA (Lago Institute of Language, Japan) |
| Laurence ANTHONY (Waseda University, Japan) |
| Michael GENUNG (Nihon University, Japan) |
| Sara GENUNG (Bard College, USA) |
| Akira HAMADA (Nihon University, Japan) |
| Takumi ISHII (University of Tsukuba, Japan) |
| Atsushi MIZUMOTO (Kansai University, Japan) |
| Chikako NISHIGAKI (Chiba University, Japan) |
| Kathryn OGHIGIAN (former Tokyo International University, Japan) |
| Kazuko TANABE (Japan Women’s University, Japan) |
| Hiroko USAMI (Tokai University, Japan) |
| Masao UTIYAMA (National Institute of Information and Communications Technology, Japan) |
| Hiroko WAKAMATSU (University of Tsukuba, Japan) |
| Kenji YOKOTA (Nihon University, Japan) |
| In alphabetical order, as of July 1, 2016 |
 http://hanamizuki2010.sakura.ne.jp/public_html/data/b48.3%20Kiyou%20SCoRE.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/TL2014-58.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/5reportnote.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/NLP2016P19-3.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/expo2016-67-68.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/b48.4%20Kiyou%20LWP.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/2014-b47.6.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/2014-b47.8.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/2013%20Nichidai%20Kiyou%20Siryo
http://hanamizuki2010.sakura.ne.jp/public_html/data/b48.3%20Kiyou%20SCoRE.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/TL2014-58.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/5reportnote.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/NLP2016P19-3.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/expo2016-67-68.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/b48.4%20Kiyou%20LWP.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/2014-b47.6.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/2014-b47.8.pdfhttp://hanamizuki2010.sakura.ne.jp/public_html/data/2013%20Nichidai%20Kiyou%20Siryo%20b46.4.pdf
http://hanamizuki2010.sakura.ne.jp/public_html/data/LLS4-19306636.pdfhttp://journals.cambridge.org/abstract_S0958344015000208
http://hanamizuki2010.sakura.ne.jp/public_html/data/A%20Meta-analysis%20of%20Data-driven%20Learning.pdf
http://hanamizuki2010.sakura.ne.jp/public_html/data/2013%20Nichidai%20Kiyou%20Note%20b46.1.pdf
Several tools have been developed in conjunction with SCoRE in order to allow learners at differing ability levels to succeed at using data-driven, or corpus-based, language learning (DDL) which involves the inductive learning of grammatical rules or regularities through the discovery of recurring patterns.
SCoRE can be best viewed in the following browsers: Chrome, Firefox, Explorer (Version 10 onwards). We recommend using Chrome or Firefox.
| 2016/7/7 | ver. 1.00 |
| Your Name | |
|---|---|
| Mail Address | |
| Grammatical Category | |
| Example Sentence |
|
| Japanese |
| Type | |
|---|---|
| Your Name | |
| Mail Address | |
| Message |